Vector embedding databases, commonly known as vector databases, are designed to deliver advanced search capabilities beyond traditional keyword or synonym-based searches. They aim to interpret the user’s intent or directly answer user queries by understanding the underlying meaning.
Semantic search and question-answering systems rely on similarity-based searches, which focus on the meaning of text or the content within images. For instance, imagine a database containing descriptions of various teas, one of which mentions that a particular tea “pairs nicely with desserts.” A simple keyword search for “tea for sweets” or even a synonym-based search might miss this tea. However, a semantic search would recognize that “desserts” and “sweets” share similar meanings, and “pairs nicely with X” implies suitability for “X,” thus successfully retrieving the relevant tea.
But how can computers replicate our human ability to grasp language nuances and similarities between words or sentences? The answer lies in a data structure known as a vector embedding (often simply called embedding or vector), which is essentially an array of numerical values. Here’s a simplified breakdown of how semantic search operates:
- When data is added or updated in the database, the vector database computes a vector embedding for each item using a specific machine learning model.
- These embeddings are stored in an optimized index, enabling rapid search operations.
- For each user query:
- The database computes a vector embedding using the same model applied to the stored data.
- A specialized algorithm identifies the embeddings closest to the query’s embedding.
The effectiveness of semantic search heavily depends on the quality of the embedding model—often proprietary or specialized—and the speed of search relies on the vector database’s performance capabilities.
What Exactly Are Vector Embeddings?
Vector embeddings are numerical representations of data designed to capture essential characteristics or semantic meanings. They represent objects mathematically within a continuous, multi-dimensional vector space, allowing efficient similarity searches.
Example of Vector Embeddings
Consider textual data: the words “automobile” and “car” share similar meanings, even though their spelling differs significantly. For semantic search to function effectively, the embeddings for “automobile” and “car” must accurately reflect their semantic closeness. This is precisely the role of vector embeddings.
In practice, embeddings are arrays of real numbers with fixed lengths (typically ranging from hundreds to thousands of dimensions), generated by specialized machine learning models. The process of converting data into embeddings is called “vectorization.” Platforms like Weaviate utilize integrations with embedding providers (such as OpenAI, Cohere, or Google PaLM) to generate and store these embeddings alongside the original data.
For example, vectorizing the words mentioned above might yield embeddings like:
automobile = [2.3, -1.1, 5.7, 14.2, 4.8, ..., 18.9]
car = [2.4, -1.0, 5.8, 14.1, 4.9, ..., 19.0]These two vectors are numerically close, indicating semantic similarity. Conversely, embeddings for unrelated words like “guitar” or “humor” would differ significantly, reflecting their semantic distance.
You might wonder what each number in the vector represents. The exact meaning of each dimension depends on the embedding model used and isn’t always intuitively clear. However, we can sometimes infer general meanings by observing correlations between vectors and familiar words.
Types of Data Suitable for Vectorization
Vector embeddings can be effectively generated for various data types. Textual data is most common, followed by images and audio (for instance, how music recognition apps identify songs from short audio clips). Additionally, embeddings can represent time-series data, 3D models, videos, chemical structures, and more.
Embeddings are generated so that semantically similar objects have vectors positioned closely within the vector space. The “distance” between vectors can be calculated using various methods, such as the sum of absolute differences between corresponding elements.
Let’s illustrate this with a simplified example:
Data Objects: lion, tiger, broccoli, carrot, airplane, bicycle
Search Query: vegetableSimplified 5-dimensional embeddings might look like this:

Even without precise calculations, it’s clear that “broccoli” and “carrot” are closer to “vegetable” than the other words, making them the top search results.
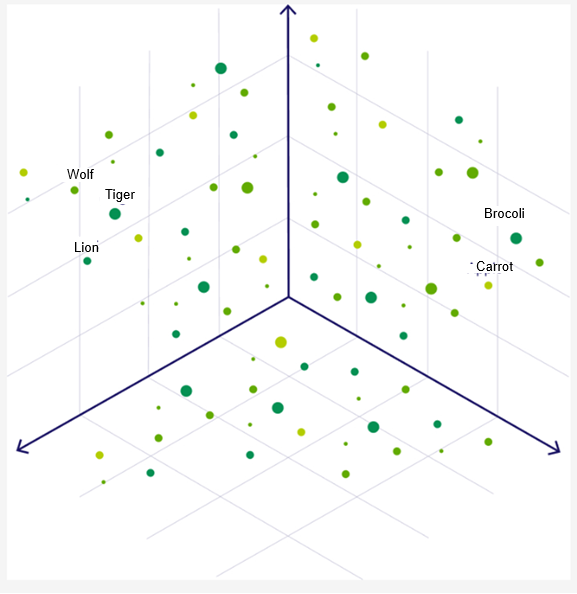
Visualizing Vector Embeddings
Imagine a simplified 3-dimensional vector space visualization. Words like “Lion” and “Tiger” would appear close together, as both are large feline predators. Nearby, but slightly further away, you might find “Wolf,” another predator but from a different family. Farther away, you’d see unrelated categories like “Broccoli” and “Carrot,” grouped closely as vegetables but distant from animals.
Summary
In this article, we’ve explored vector embeddings, the foundational technology behind vector databases and semantic search.
To recap, vector embeddings are numerical representations of various data types—text, images, audio, and more—generated by machine learning models. These embeddings capture semantic relationships between data points, enabling efficient similarity searches. This approach, known as similarity search, powers numerous applications, including semantic text search, image retrieval, and recommendation systems.
By understanding and leveraging vector embeddings, we can build smarter, more intuitive search experiences that align closely with human understanding.